


The Achilles' Heel of AI: Why DeepSeek and Other Advanced Models Struggle with Overthinking


Recent research from Tencent AI Lab, Soochow University, and Shanghai Jiao Tong University has uncovered a fascinating weakness in advanced AI models like DeepSeek-R1: they often suffer from "underthinking" – frequently abandoning correct solution paths in favor of exploring new approaches.
The "Underthinking" Phenomenon
When facing complex problems, these AI models behave like unfocused students, constantly switching between different solution strategies instead of deeply exploring promising paths. The research shows that in incorrect answers, models:
Use 225% more tokens than in correct answers
Increase thought-switching frequency by 418%
Abandon potentially correct solutions prematurely

Key Research Findings
Model Behavior Analysis
The study focused on several advanced models, including:
DeepSeek-R1-671B
QwQ-32B-Preview
Other o1-style models
Testing was conducted across three challenging datasets:
MATH500
GPQA Diamond
AIME2024
Statistical Evidence

The research revealed striking statistics:
70% of incorrect answers contained at least one correct approach
50% of wrong answers had over 10% correct reasoning paths
Models frequently abandoned promising solutions after minimal exploration
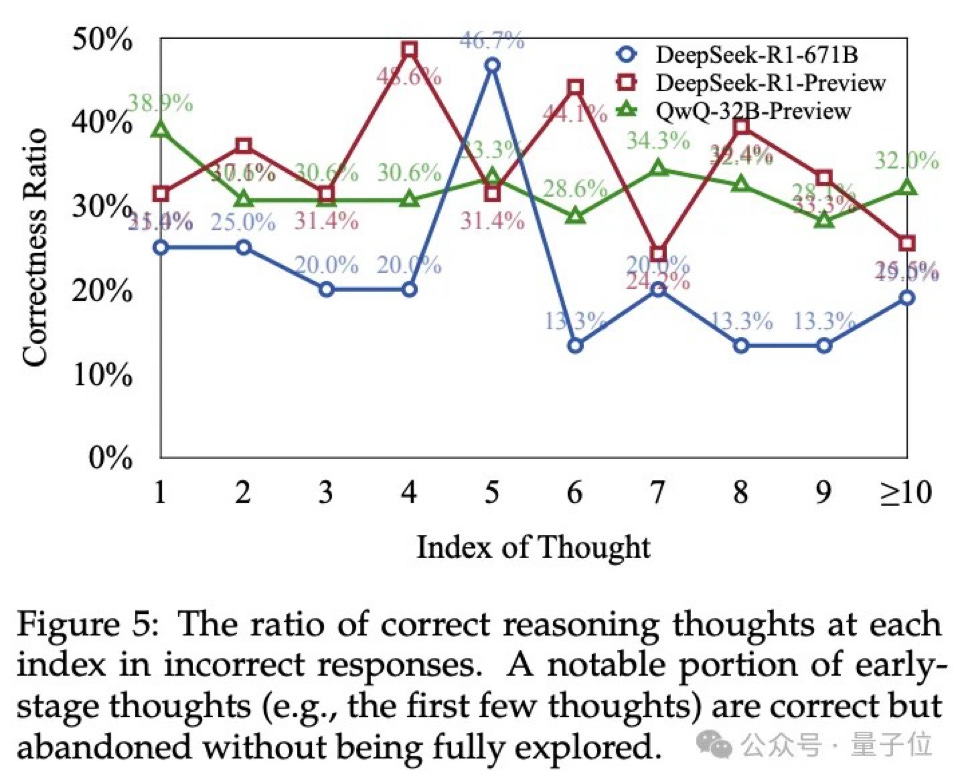

Real-World Example

In one illustrative case, the model:
Correctly identified an elliptical equation problem
Started with the right approach
Abandoned the solution prematurely
Consumed 7,270 additional tokens exploring alternative paths
Failed to reach the correct answer
Measuring the Problem
The researchers developed an "Underthinking Metric" (UT) to quantify this behavior:
Measures token usage efficiency
Evaluates reasoning effectiveness
Tracks the ratio of useful to total tokens used

The Berkeley Connection
UC Berkeley professor Alex Dimakis independently observed a related phenomenon:
Correct answers tend to be significantly shorter
Incorrect answers involve excessive explanation
Simple solutions often indicate accuracy
Proposed Solutions
1. Thought Switching Penalty (TSP)
This mechanism:
Penalizes frequent strategy changes
Forces models to explore current paths longer
Mimics successful human problem-solving strategies
Results show:
Accuracy increased from 41.7% to 45.8% on AIME2024
UT Score decreased from 72.4 to 68.2
No model retraining required

2. Laconic Decoding
Professor Dimakis's approach:
Run the model 5 times in parallel
Select the answer with the fewest tokens
Achieves 6-7% accuracy improvement
Outperforms consensus decoding

Industry Implications
This research has significant implications for AI development:
Highlights the need for better reasoning strategies
Questions the "more tokens = better results" assumption
Suggests simpler solutions might be more reliable
Offers practical improvements without model retraining
Looking Forward
These findings could revolutionize how we approach AI model development:
Focus on depth rather than breadth in reasoning
Implement penalties for excessive strategy switching
Prefer concise solutions over verbose explanations
Design models that better mimic successful human problem-solving patterns
#AIResearch #MachineLearning #DeepSeek #AIOptimization #TechInnovation