


Open Reasoner Zero: A Breakthrough in AI Training Efficiency Matches DeepSeek with Just 1/30th of Training Steps
Major AI Figures Including Kai-Fu Lee, Harry Shum, and Xiangyu Zhang Unveil Revolutionary Open-Source Training Method

https://github.com/Open-Reasoner-Zero/Open-Reasoner-Zero/
In a significant development for the AI community, Jump Computing (阶跃星辰) and Tsinghua University have jointly released Open Reasoner Zero (ORZ), a groundbreaking open-source project that achieves comparable performance to DeepSeek-R1-Zero with dramatically reduced training requirements. This development comes at a time when DeepSeek has open-sourced various components but notably withheld their training code and data.
Revolutionary Efficiency
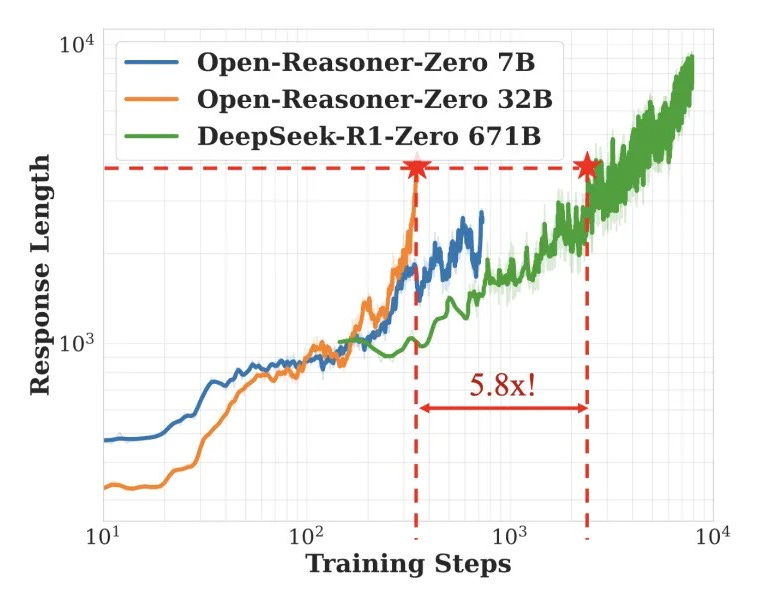
The most striking aspect of ORZ is its remarkable efficiency: it requires only 1/30th of the training steps to match the performance of similarly-sized DeepSeek-R1-Zero distilled from Qwen. In terms of response length, the system achieves parity with DeepSeek-R1-Zero 671B using just 17% of the training steps, representing a significant advancement in training efficiency.
Key Technical Insights
The research team, led by AI luminaries including Harry Shum, Daxin Jiang, and ResNet creator Xiangyu Zhang, made several crucial discoveries that challenge current assumptions in the field. Perhaps most surprisingly, they found that complex reward functions may be unnecessary for effective training.
Their experiments demonstrated that a minimalist approach using vanilla PPO with GAE (Generalized Advantage Estimation) could effectively scale RL training. The key parameters they identified were:
GAE λ = 1
Discount factor γ = 1
Rule-based reward functions
The "Aha Moment"
One of the most intriguing findings was the identification of a critical turning point around the 680th training step, where the model simultaneously showed significant improvements in:
Training reward values
Reflection capabilities
Response length
This phenomenon mirrors the "aha moment" previously described in DeepSeek-R1-Zero's research, suggesting a common pattern in how these models develop advanced capabilities.
Technical Breakthroughs
The team achieved stable training without relying on KL-based regularization techniques, contradicting current wisdom in the RLHF and reasoning model domains. This success opens new possibilities for scaling reinforcement learning further.
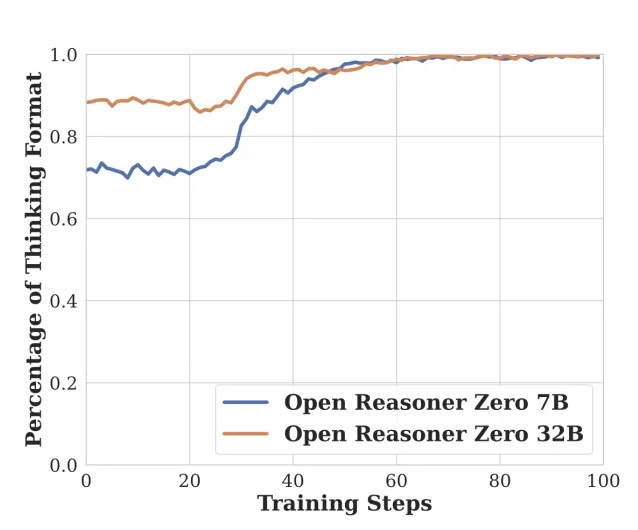
Using Qwen2.5-Base-7B as the foundation model, the researchers observed sudden increases in rewards and response lengths across all benchmarks at certain points, suggesting emergent behavior patterns. Notably, the Average Correct Reflection Length consistently exceeded the Average Response Length throughout training.
Data Insights
The research revealed crucial insights about training data requirements. While training on limited academic datasets like MATH led to quick performance plateaus, carefully curated large-scale diverse datasets enabled continuous scaling without saturation in either training or test sets.
Performance Metrics
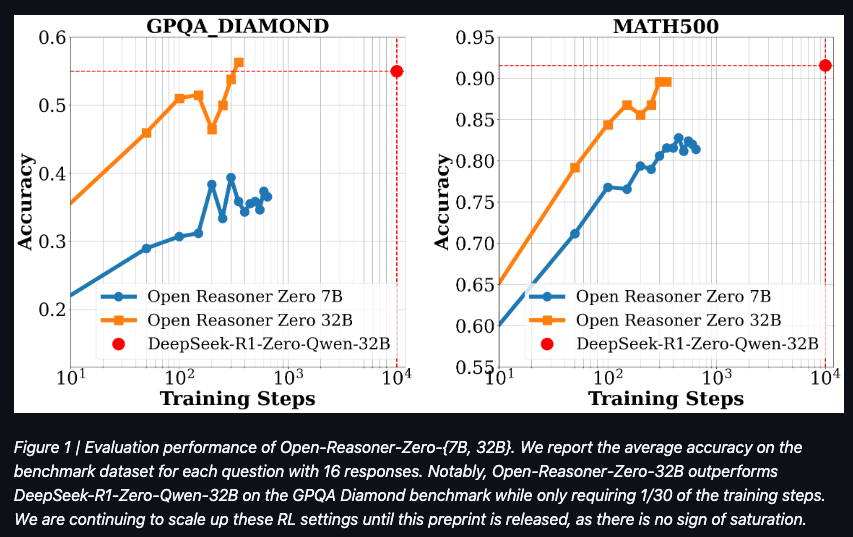
The Open-Reasoner-Zero model achieved impressive results, surpassing Qwen2.5 Instruct on both MMLU and MMLU_PRO benchmarks without requiring additional instruction tuning. This performance validates the efficiency of their training approach and the effectiveness of their minimalist methodology.
Open Source Commitment
Unlike some competitors, the team has fully embraced open source principles by releasing:
Training data
Training code
Research paper
Model weights All under the permissive MIT License. Within 48 hours of release, the project garnered over 700 stars on GitHub, demonstrating strong community interest.

Future Implications
This research has significant implications for the field of AI development:
Training Efficiency: The dramatic reduction in required training steps could make advanced AI development more accessible to smaller organizations and research teams.
Methodological Simplification: The success of simpler training approaches challenges the trend toward increasingly complex methodologies.
Resource Optimization: The ability to achieve comparable results with fewer training steps could significantly reduce the computational resources required for AI development.

Ongoing Development
During Jump Computing's recent ecosystem open day, CEO Daxin Jiang briefly mentioned this research, noting it as a work in progress with potential new developments on the horizon. This suggests that while the current results are impressive, further improvements may be forthcoming.
The success of ORZ demonstrates that effective AI training doesn't necessarily require complex reward functions or extensive training steps, potentially democratizing access to advanced AI development. As the project continues to evolve, it may further reshape our understanding of efficient AI training methodologies.
#AIResearch #MachineLearning #OpenSource #DeepLearning #ReinforcementLearning #AITraining #TechInnovation