
How to Run DeepSeek-V3 on 8 Mac Minis: A DIY Approach to Local AI

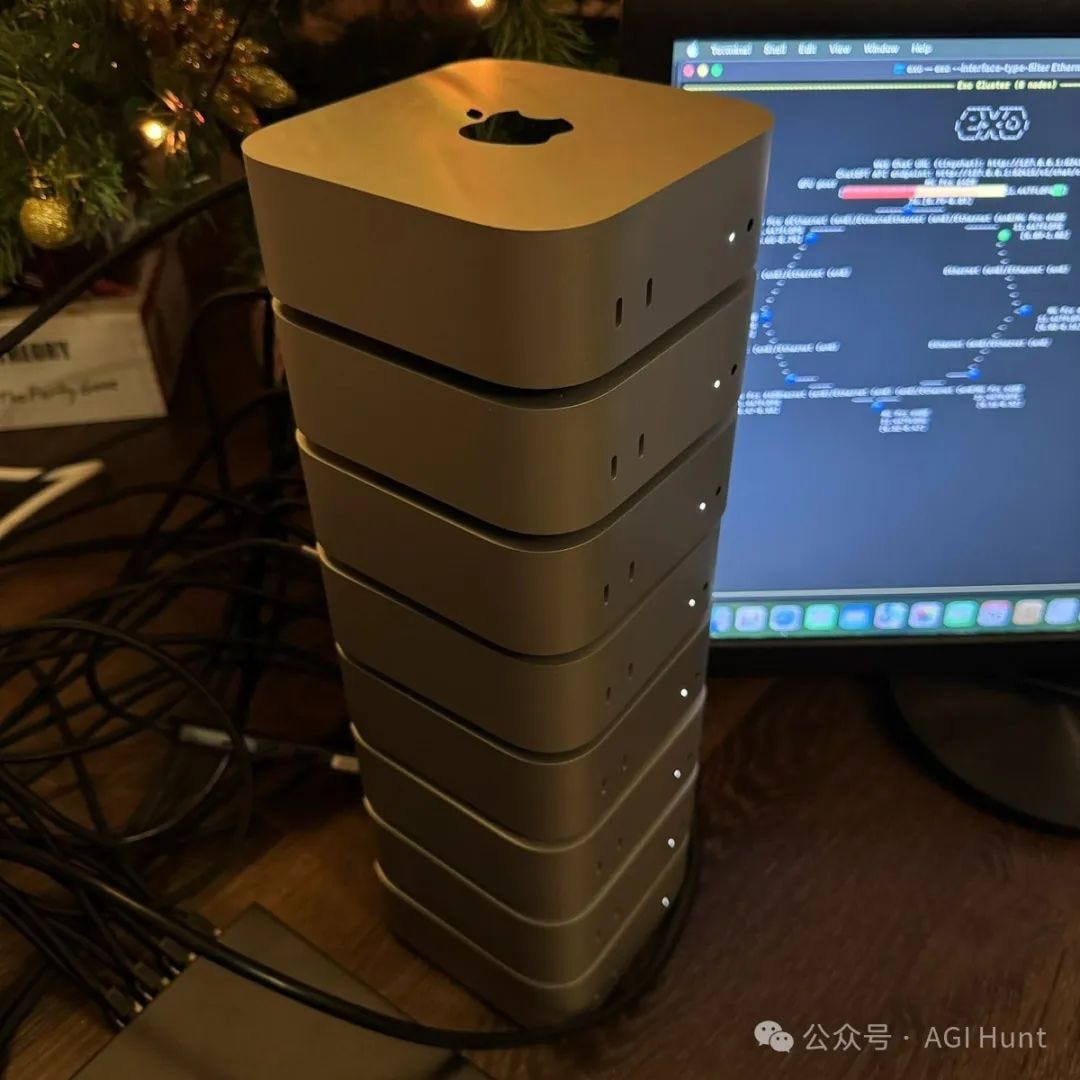
A developer recently stacked 8 Mac Minis into a "mini data center" to run large language models locally. Here's what you need to know:
Setup Details
Cost: ~$20,000 total
Performance: 5 tokens/second
Hardware: 8x M4 Mac Minis in stack configuration
Implementation: Distributed computing across units

Cost-Performance Analysis
Compared to commercial servers:
Professional setups: $200,000+
This DIY approach: $20,000
Performance trade-off: Significantly slower but locally controlled
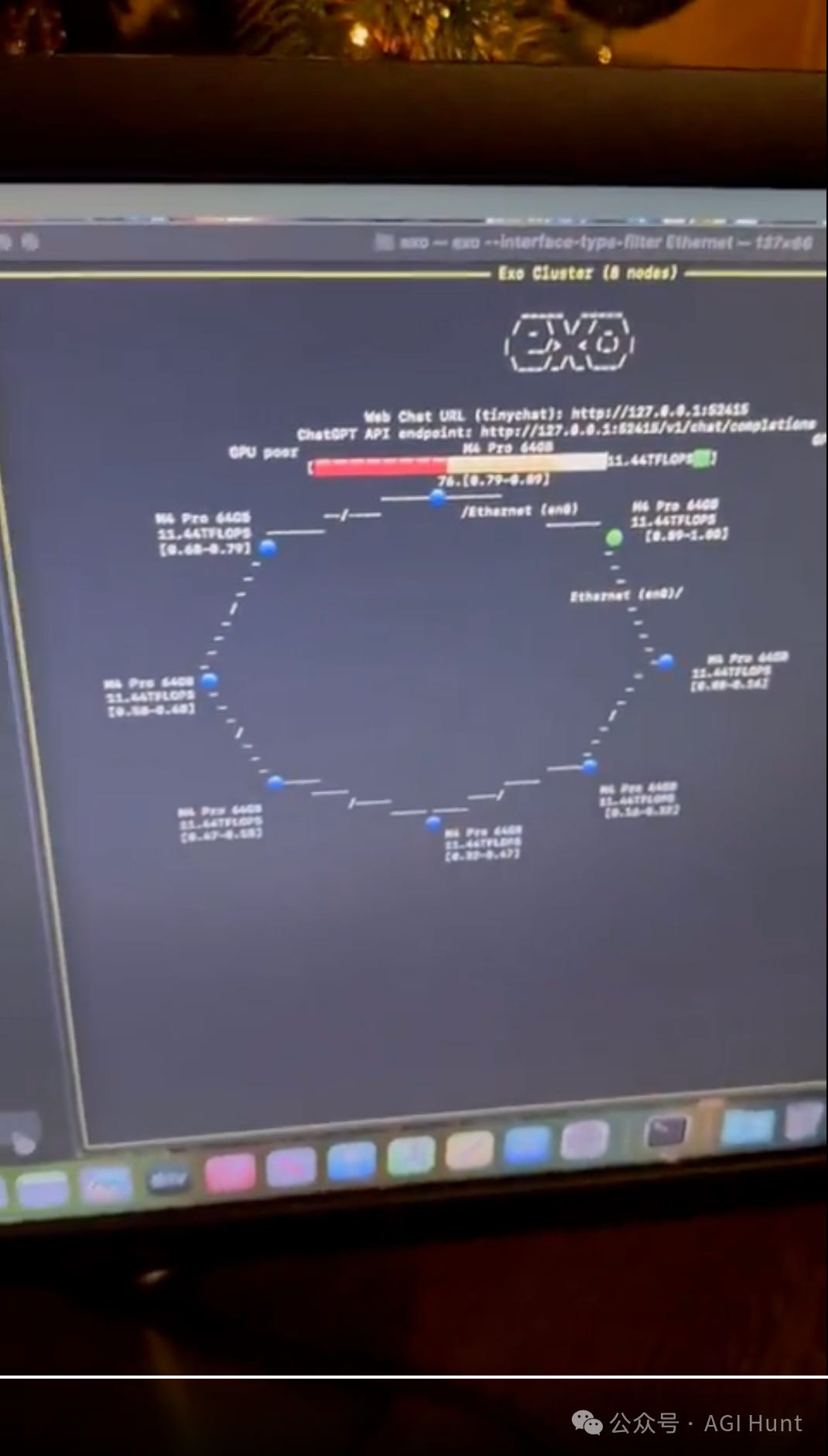
Technical Implementation
The system uses distributed computing to coordinate the Mac Minis, enabling local LLM inference without dependence on cloud services.
Practical Considerations
Pros:
Local control
Lower initial investment
Consumer hardware availability
Cons:
Lower performance vs. commercial servers
Power consumption concerns
Heat management needed
While not optimal for production use, this setup demonstrates the possibilities for experimenting with LLMs using consumer hardware. It's particularly relevant for developers and researchers who want to test models locally without significant cloud computing costs.
#AIComputing #MacMini #LocalAI #DIY #TechExperiment
Is it really used the Mac's GPU cores?...
And, any stable way to actually use 'Apple GPUs' for NN trains and inferences?
5 tokens per second is … not too bad