
DeepSeek's Latest Shocker: Who Needs CUDA Anyway?
How Assembly-Level PTX Programming Achieved 10x Efficiency Over CUDA


DeepSeek model development actually bypassed CUDA? Latest reports claim that the DeepSeek team took an unconventional path - optimizing NVIDIA GPU's low-level assembly language PTX to achieve maximum performance. Industry insiders are asking: Does CUDA's moat no longer exist?
Originally, DeepSeek's low-cost training of R1 had already made Silicon Valley and Wall Street tremble.
And now it's revealed that building this super AI doesn't even need CUDA?
According to foreign media reports, in just two months, they trained a 671 billion parameter MoE language model on a cluster of 2,048 H800 GPUs, achieving 10 times higher efficiency than top AI systems.
This breakthrough wasn't achieved using CUDA, but through extensive fine-grained optimization and using NVIDIA's assembly-level PTX (Parallel Thread Execution) programming.

This news once again upended the AI community, with netizens expressing shock at their strategy:
"If there's any group of people in this world crazy enough to say 'CUDA is too slow! Let's just write PTX directly!' it would definitely be those former quantitative traders."
Some people asked what it would mean if DeepSeek open-sourced their CUDA alternative.


Genius Geeks Fine-tune PTX, Pushing GPU Performance to the Extreme
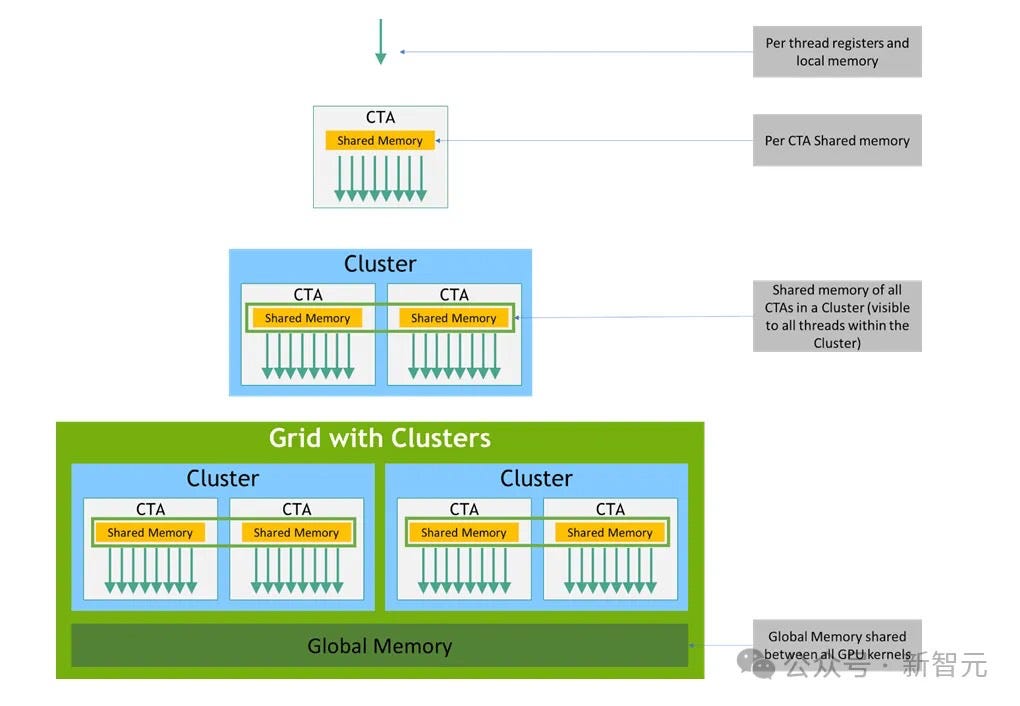
NVIDIA PTX (Parallel Thread Execution) is an intermediate instruction set architecture specifically designed for its GPUs, positioned between high-level GPU programming languages (like CUDA C/C++ or other language frontends) and low-level machine code (Stream Assembly or SASS).
PTX is a near-bottom-level instruction set architecture that presents the GPU as a data-parallel computing device, enabling fine-grained optimizations like register allocation and thread/warp-level adjustments that are impossible with languages like CUDA C/C++.
When PTX is converted to SASS, it's optimized for specific generations of NVIDIA GPUs.

When training the V3 model, DeepSeek reconfigured NVIDIA H800 GPUs: Out of 132 streaming multiprocessors, 20 were allocated for inter-server communication, mainly for data compression and decompression, to break through processor connection limitations and improve transaction processing speed.
To maximize performance, DeepSeek also implemented advanced pipelining algorithms through additional fine-grained thread/warp-level adjustments.
These optimizations far exceed conventional CUDA development levels but are extremely difficult to maintain. However, this level of optimization perfectly demonstrates the DeepSeek team's exceptional technical capabilities.

This is because, under the dual pressure of GPU shortages and U.S. restrictions, companies like DeepSeek had to seek innovative solutions.
Fortunately, they achieved major breakthroughs in this area.
Some developers believe that "low-level GPU programming is the right direction. The more optimization, the more costs can be reduced, or performance budget can be increased for other improvements without additional expenditure."

Market Impact and CUDA's Moat
This breakthrough has caused significant market impact, with some investors believing that the demand for high-performance hardware will decrease for new models, potentially affecting sales performance of companies like NVIDIA.
However, industry veterans including former Intel chief Pat Gelsinger believe that AI applications can fully utilize all available computing power.
Regarding DeepSeek's breakthrough, Gelsinger sees it as a new way to embed AI capabilities in various low-cost devices in the mass market.

Does CUDA's Moat No Longer Exist?
Does DeepSeek's emergence mean that large-scale GPU clusters are no longer needed for frontier LLM development?
Will the massive investments in computing resources by Google, OpenAI, Meta, and xAI ultimately go to waste? AI developers' general consensus suggests not.
However, it's certain that there's still enormous potential to be tapped in data processing and algorithm optimization, and more innovative optimization methods will emerge in the future.
With DeepSeek's V3 model being open-sourced, their technical report discloses relevant details.
The report documents DeepSeek's deep low-level optimizations. In simple terms, their optimization level can be summarized as "they rebuilt the entire system from the bottom up."
As mentioned above, when training V3 using H800 GPUs, DeepSeek customized the GPU core computing units (Streaming Multiprocessors, or SMs) to meet specific needs.

Technical Barriers Still Exist
Regarding this, netizen Ian Cutress states: "Deepseek's use of PTX doesn't eliminate CUDA's technical barriers."
CUDA is a high-level language. It makes codebase development and interfacing with NVIDIA GPUs simpler while supporting rapid iterative development.
CUDA can optimize performance by fine-tuning bottom-level code (PTX), and its fundamental libraries are already complete. Currently, the vast majority of production-level software is built on CUDA.
PTX is more like a directly understandable GPU assembly language. It works at the bottom level, allowing for microscopic optimizations.
Choosing to program in PTX means those pre-built CUDA libraries mentioned above can't be used. This is an extremely tedious task requiring deep professional knowledge of hardware and runtime issues.
However, if developers fully understand what they're doing, they can indeed achieve better performance and optimization effects at runtime.
Currently, NVIDIA's ecosystem still mainly uses CUDA.
Developers hoping to extract an additional 10-20% performance or power efficiency from their compute loads, such as companies deploying models in the cloud and selling token services, have indeed deepened their optimization from CUDA to PTX level. They're willing to invest time because this investment is worthwhile in the long run.
It's worth noting that PTX is usually optimized for specific hardware models and is difficult to port between different hardware without specially written adaptation logic.
Additionally, manually tuning compute kernels requires tremendous perseverance, courage, and the special ability to stay calm, as programs might encounter memory access errors every 5000 cycles.
Of course, we fully understand and respect those scenarios that genuinely need to use PTX and developers who receive sufficient compensation to handle these issues.
As for other developers, continuing to use CUDA or other CUDA-based high-level variants (or MLIR) remains the wise choice.
I don't know enough about this stuff but am I right in thinking that if you had the expertise to pull this off then doing the same for an eventual home (China) developed GPU would not be too much of an ask?
you open by saying deepseek got 10x improvement, and then end by implying that it requires tremendous effort for 10% improvement. what's the disconnect?