DeepSeek Launches Janus-Pro: A New Multimodal Model Challenging DALL-E 3 with Just Two Weeks of Training and 256 A100 GPUs

Just as the world was watching, DeepSeek made another move on Chinese New Year's Eve. DeepSeek officially released Janus-Pro, an integrated multimodal large language model combining understanding and generation capabilities. The code and model have been completely open-sourced.
Technical Architecture and Innovation
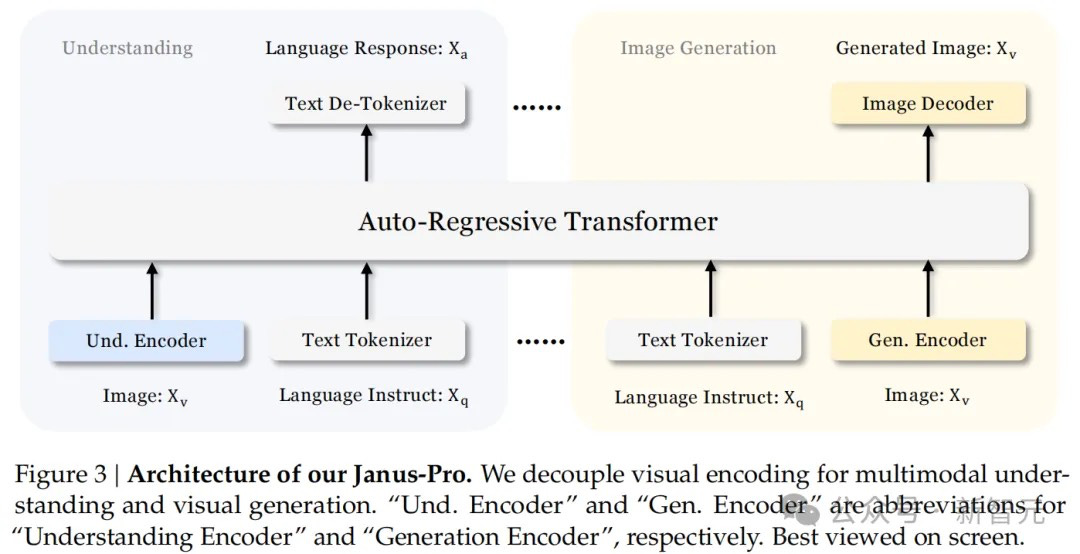
Janus-Pro employs an innovative autoregressive framework and achieves unification of multimodal understanding and generation, representing a comprehensive upgrade from last year's Janus model. By decoupling visual encoding into independent channels, it overcomes the limitations of previous methods while still utilizing a single unified Transformer architecture for processing. This decoupling not only alleviates the inherent role conflict of visual encoders in understanding and generation but also significantly enhances framework flexibility.

Efficient Training Approach
Staying true to form, DeepSeek used remarkably minimal computing power:
The 1.5B and 7B models were trained on clusters with 16/32 compute nodes
Each node equipped with 8 Nvidia A100 (40GB) GPUs
Total training time approximately 7/14 days

Performance and Real-World Testing
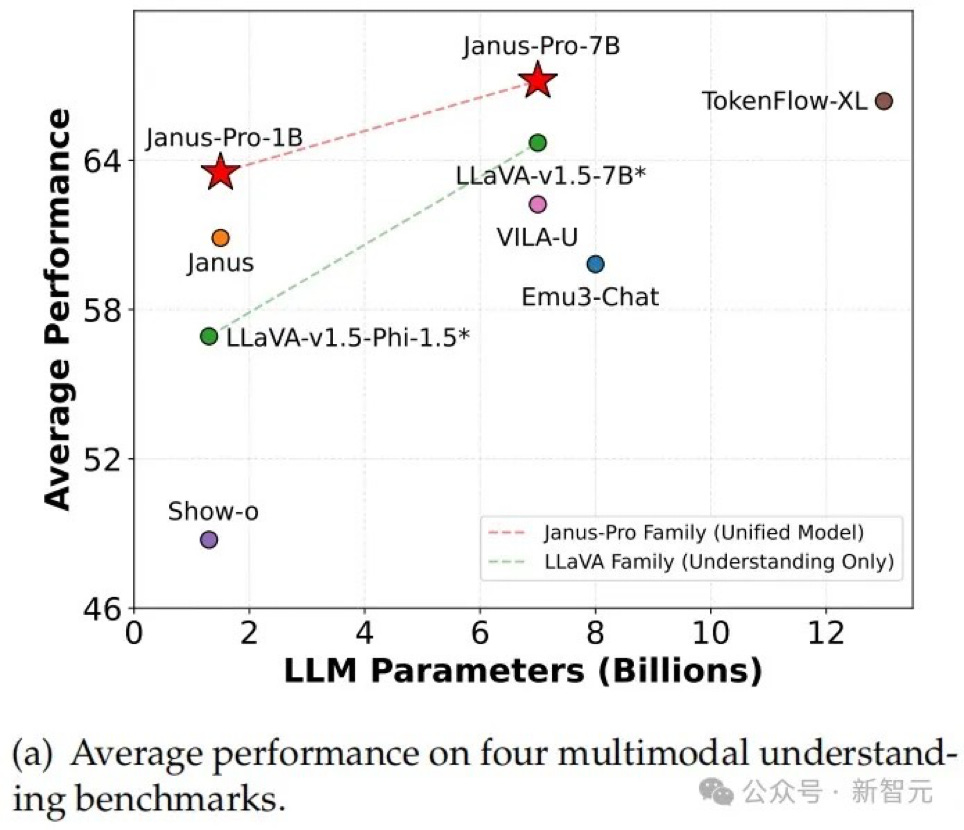
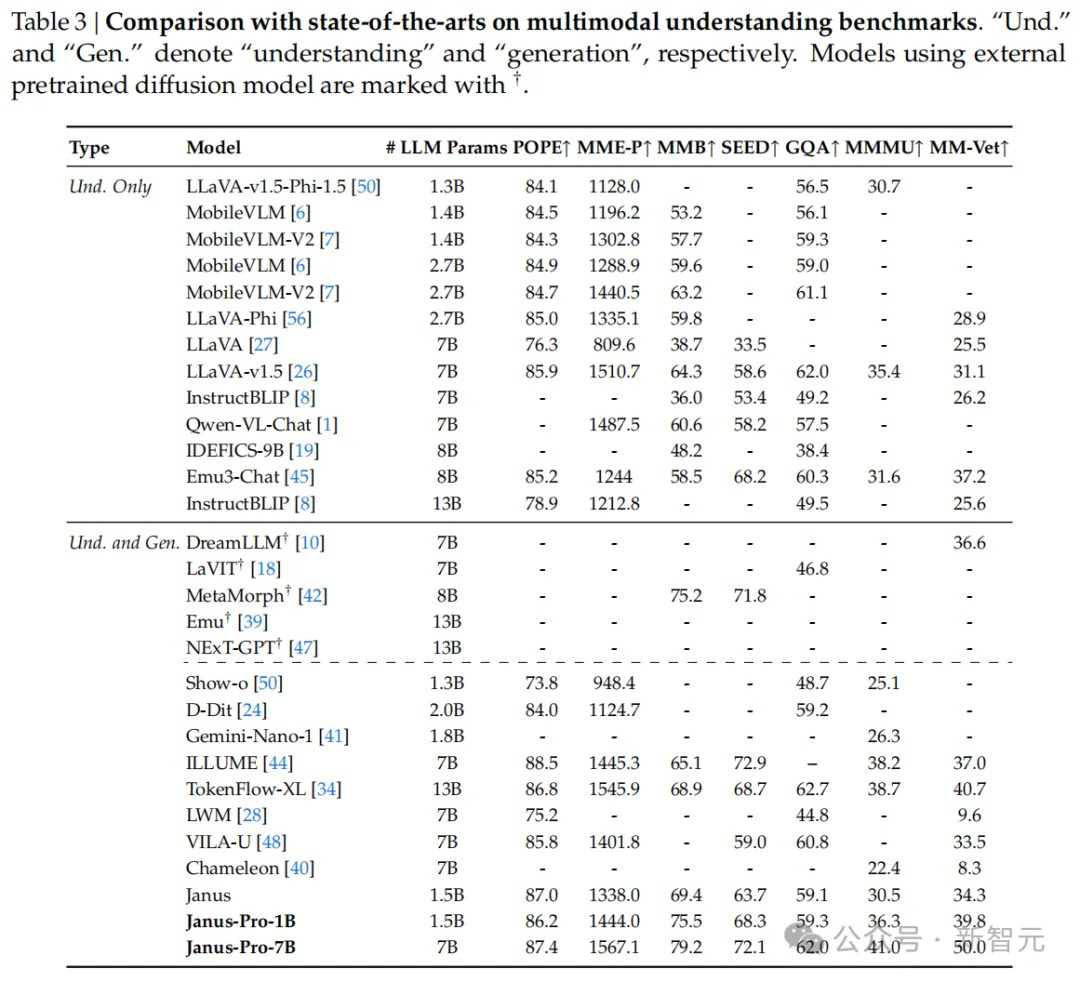
Results show that the upgraded Janus-Pro achieved significant breakthroughs in both multimodal understanding and text-to-image capabilities, while also improving generation stability. In benchmark tests:
Achieved 79.2 score on MMBench, surpassing Janus (69.4), TokenFlow (68.9), and MetaMorph (75.2)
Scored 0.80 on GenEval text-to-image instruction execution, outperforming Janus (0.61), DALL-E 3 (0.67), and Stable Diffusion 3 Medium (0.74)
User testing has shown mixed results:
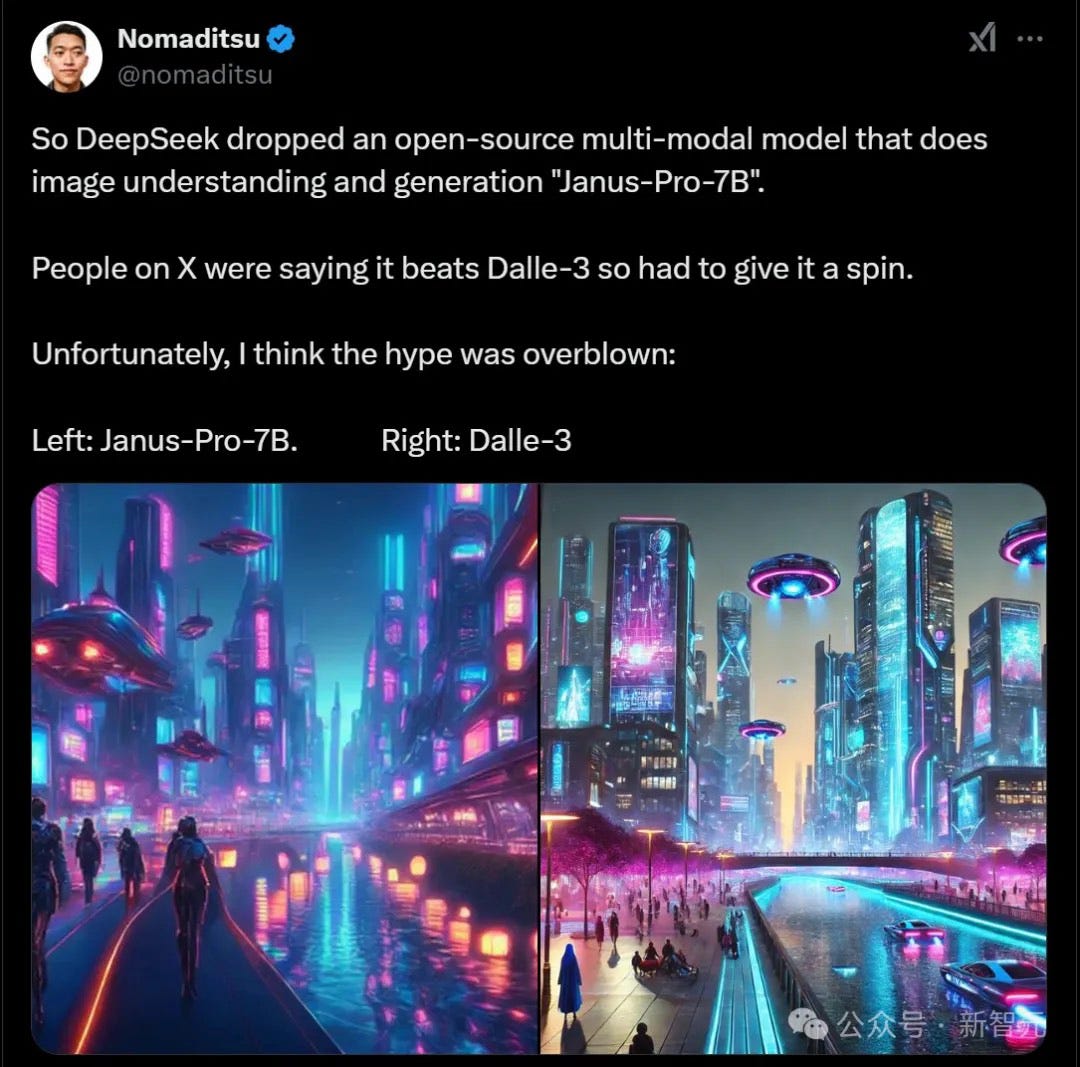
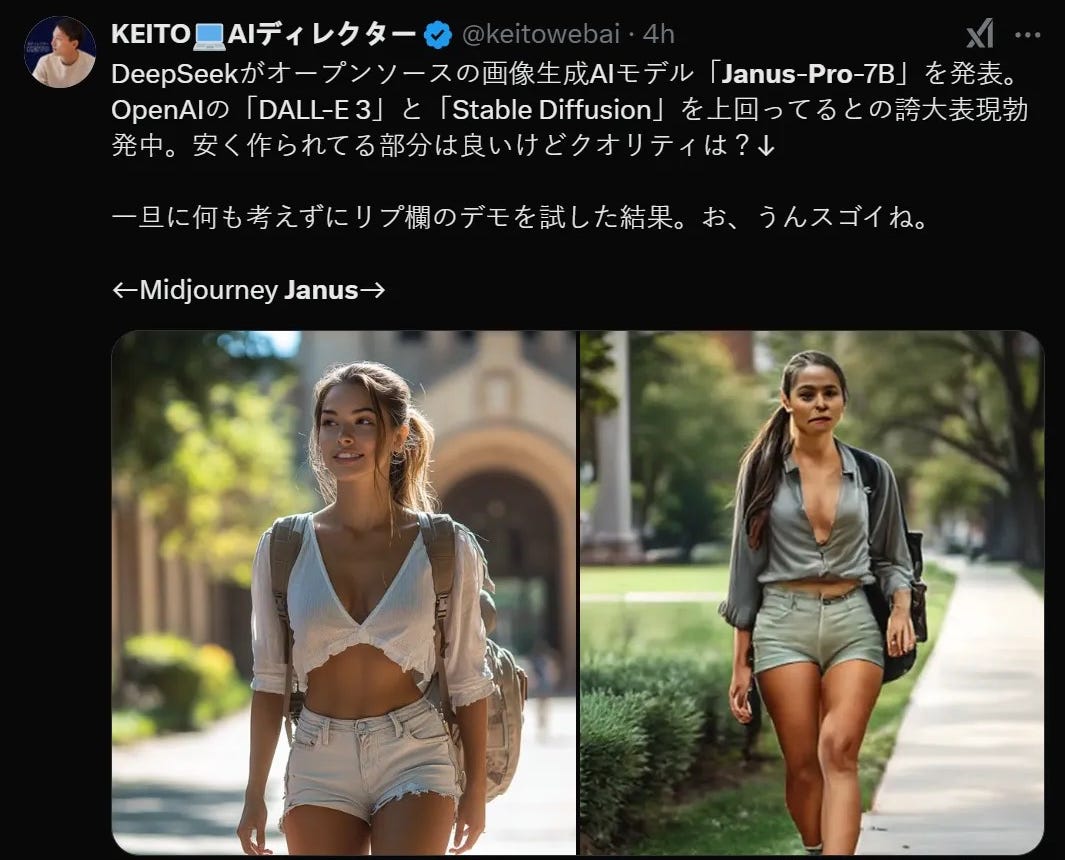
Some users found Janus-Pro's image generation results less than ideal
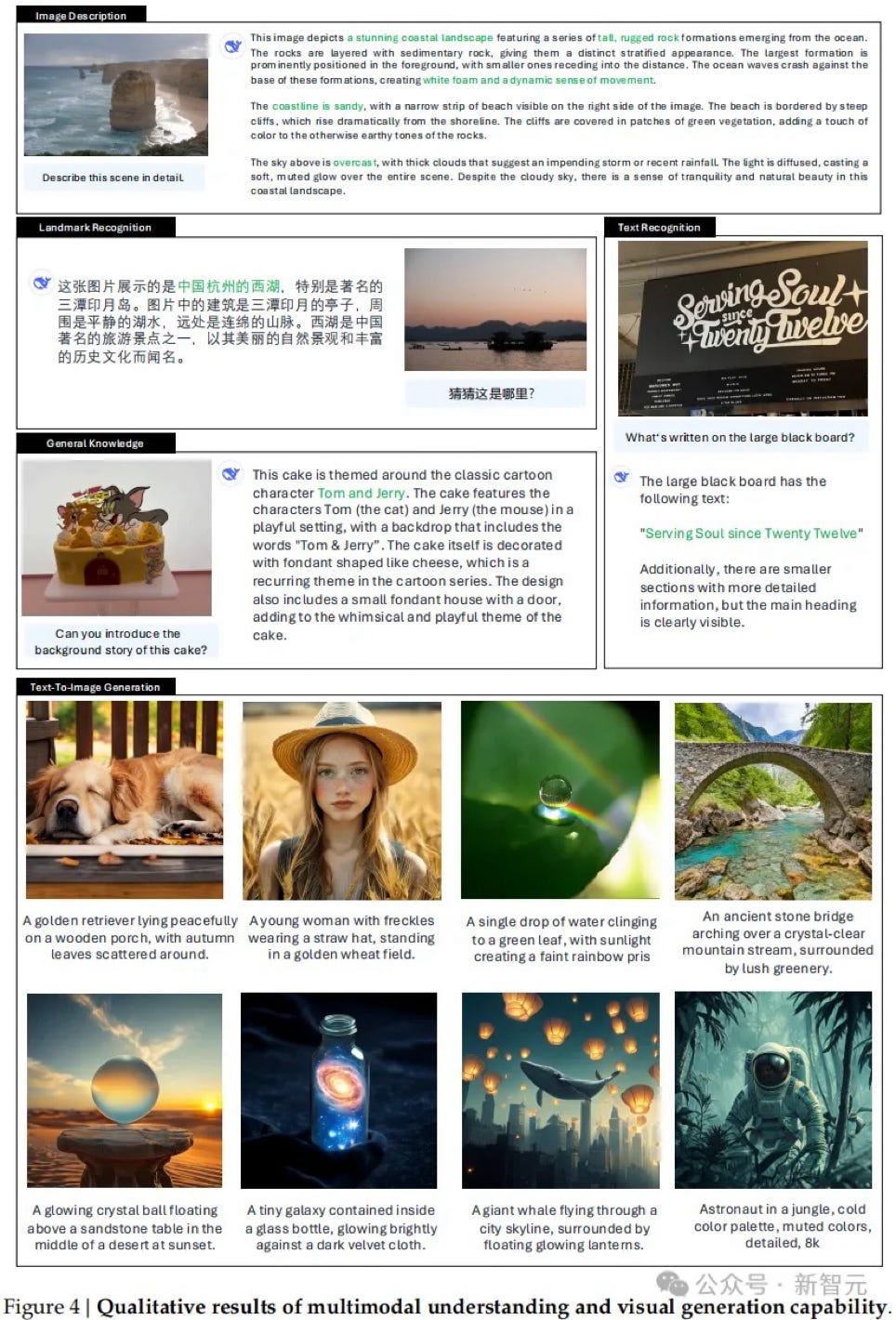
Others demonstrated successful cases in both image generation and understanding
The 1B model can run directly in browsers using WebGPU


Technical Details
Core Architecture
Janus-Pro's architecture centers on decoupling visual encoding in multimodal understanding and generation tasks. It employs:
SigLIP encoder for multimodal understanding, extracting high-dimensional semantic features
VQ tokenizer for visual generation, converting images to discrete ID sequences
Understanding and generation adapters for mapping features to language model input space
Unified processing through a single large language model

Training Strategy Improvements
The team optimized the three-stage training process:
Extended Phase I training with ImageNet data
Focused Phase II training on standard text-to-image data
Adjusted data ratios in Phase III from 7:3:10 to 5:1:4 for multimodal, pure text, and text-to-image data
Data Scaling
Significant expansion in training data:
Added 90 million training samples for multimodal understanding
Incorporated 72 million synthetic aesthetic data samples for visual generation
Achieved 1:1 ratio between real and synthetic data in unified pre-training
Current Limitations
The model faces several challenges:
384×384 input resolution limits OCR task performance
Lower resolution affects generated image details
Face generation shows inconsistencies at smaller scales
Visual token encoder's reconstruction loss impacts detail rendering
These limitations are expected to improve with future resolution enhancements.