


DeepGEMM: DeepSeek Unveils High-Performance Matrix Multiplication Library on Day 3 of Open Source Week
Small Team, Mighty Impact! Unleashing the Power of Open Source with DeepGEMM.

DeepSeek's Open Source Week has reached its third day, with the "small but mighty" team continuing to demonstrate the substantial power of open source. Following the release of FlashMLA and DeepEP on days one and two, the team has now unveiled DeepGEMM, a clean and efficient library designed specifically for FP8 general matrix multiplication with fine-grained scaling capabilities.
The Open Source Initiative
DeepSeek's team announced on day zero that they would be open-sourcing five repositories over the course of a week. These repositories contain core components used in their online services, all thoroughly documented, deployed, and battle-tested in production environments.
Their philosophy is refreshingly straightforward: every line of shared code contributes to collective progress and accelerates the journey toward artificial general intelligence (AGI). This isn't about ivory tower academics, but about garage-style energy and community-driven innovation.
Previous Releases Recap
Before diving into DeepGEMM, it's worth reviewing the previous two days' releases:
On day one, DeepSeek shared FlashMLA, an efficient MLA decoding kernel optimized for Hopper GPUs and variable-length sequences. This implementation supports BF16, features paged KV cache with block size 64, and achieves impressive performance metrics: 3000 GB/s memory bandwidth and 580 TFLOPS compute capability on H800 GPUs.

Day two brought DeepEP, the first open-source EP communication library specifically designed for training and inferencing Mixture-of-Experts (MoE) models. It features efficient all-to-all communication, supports both intranode and internode communication via NVLink and RDMA, provides high-throughput kernels for training and inference prefilling, offers low-latency kernels for inference decoding, natively supports FP8 dispatch, and enables flexible GPU resource control for computation-communication overlapping.

DeepGEMM: The Latest Innovation
Today's release, DeepGEMM, represents another significant step forward. This FP8 GEMM library supports both dense GEMM and MoE GEMM operations while providing support for DeepSeek's V3 and R1 training and inference needs.
DeepGEMM achieves remarkable performance, delivering up to 1350+ FP8 TFLOPS on Hopper GPUs. What sets it apart is its clean design philosophy – the library has minimal dependencies and operates with Just-In-Time compilation. Despite consisting of only about 300 lines of core code, DeepGEMM outperforms expert-tuned kernels across various matrix shapes.
Key Features
DeepGEMM's standout characteristic is its clean, efficient design. It supports both regular and Mixture-of-Experts (MoE) grouped GEMM operations, is implemented in CUDA but requires no compilation for installation, uses lightweight Just-In-Time (JIT) module compilation for all kernels at runtime, is specifically designed for NVIDIA Hopper Tensor Cores, and leverages CUDA core two-level accumulation to address precision issues with FP8 tensor core accumulation.
While DeepGEMM borrows some concepts from CUTLASS and CuTe, it deliberately avoids overdependence on their templates and algebra. The entire library's core kernel functions consist of only about 300 lines of code, making it an excellent resource for learning Hopper FP8 matrix multiplication and optimization techniques.
Performance Benchmarks
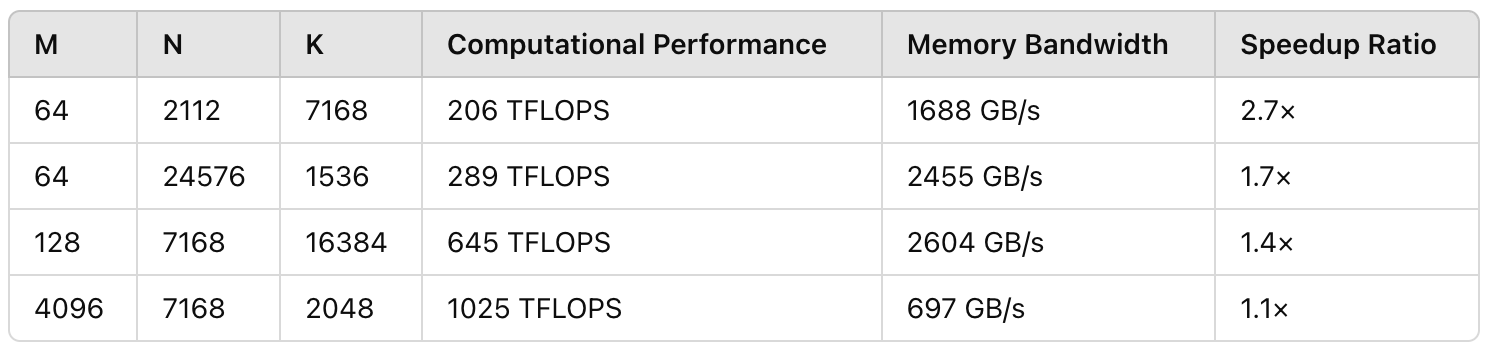
DeepGEMM's performance is impressive. Testing was conducted on H800 using NVCC 12.8 with all shapes potentially used in DeepSeek-V3/R1 inference (including prefilling and decoding, but excluding tensor parallelism). All acceleration metrics were calculated by comparing with internal optimizations based on CUTLASS 3.6.
For regular (non-grouped) GEMM operations, the results are remarkable:
For grouped GEMM with continuous layout, DeepGEMM also shows significant performance improvements:

Technical Innovations
DeepGEMM employs several optimization techniques, some of which aren't available in CUTLASS:

Persistent Thread Block Specialization: Overlapping data movement, tensor core MMA instructions, and CUDA core accumulation.
Hopper TMA Features: Using Tensor Memory Accelerator for faster, asynchronous data movement, loading matrices and scaling factors, storing output matrices, and supporting multicast and descriptor prefetching.
General Detail Optimizations: Using stmatrix PTX instructions, register count control for different thread block groups, and maximizing operation overlapping.
Unified Optimized Block Scheduler: One scheduler for all non-grouped and grouped kernels, using tiling to improve L2 cache reuse.
Full JIT Design: All kernels are compiled at runtime using lightweight JIT, treating GEMM shape, block size, and pipeline stages as compile-time constants, automatically selecting optimal parameters, and fully unrolling MMA pipelines.
Non-Aligned Block Sizes: Supporting non-aligned block sizes like 112 to enable more SMs to work.
FFMA SASS Interleaving: Modifying FFMA instructions in the compiled binary, flipping yield and reuse bits to create more opportunities for overlapping MMA instructions and enhancing FFMA instruction performance.
Implementation and Usage
Using DeepGEMM requires:
Hopper architecture GPU with sm_90a support
Python 3.8 or higher
CUDA 12.3 or higher (12.8+ recommended for best performance)
PyTorch 2.1 or higher
CUTLASS 3.6 or higher (via Git submodule clone)
Installation is straightforward with python setup.py install, after which DeepGEMM can be imported into Python projects.
The library provides three main types of GEMM operations:
Regular dense GEMM (non-grouped) via
deep_gemm.gemm_fp8_fp8_bf16_ntGrouped GEMM with continuous layout via
m_grouped_gemm_fp8_fp8_bf16_nt_contiguousGrouped GEMM with masked layout via
m_grouped_gemm_fp8_fp8_bf16_nt_masked
Additionally, utility functions are available for controlling SM usage, obtaining alignment requirements, and handling TMA-aligned tensors.
Significance in the AI Landscape
In the era of compute-intensive AI large models, efficient matrix operations are critical for performance. DeepGEMM's optimization of FP8 GEMM operations can significantly enhance model training and inference speeds while maintaining high precision.
For large models like DeepSeek-V3, DeepGEMM provides up to 2.7x performance improvement, translating to faster inference speeds and lower computational costs. This is particularly valuable as the industry pushes toward more efficient AI implementation.
Perhaps more importantly, DeepGEMM's open-source nature provides a valuable resource for the entire AI community. Its clean design makes it easier for developers to understand and learn FP8 matrix multiplication and optimization techniques, potentially advancing the entire field.
Looking Forward
DeepSeek's Open Source Week continues, with two more days of releases to come. The community is speculating about what might be next – perhaps R2 or even something AGI-related?
Whatever comes next, DeepSeek's commitment to open source is clear. By sharing these core components of their technology stack, they're not just showcasing their capabilities but also contributing to the broader AI ecosystem's advancement.
The GitHub repository for DeepGEMM is available at https://github.com/deepseek-ai/DeepGEMM for those interested in exploring or implementing this technology in their own work.
DeepSeek's approach demonstrates that sometimes the most powerful innovations come not from secretive development but from open collaboration and community-driven progress. As AI development continues to accelerate, tools like DeepGEMM that balance performance with accessibility will play an increasingly important role in democratizing access to cutting-edge capabilities.
#DeepSeek #DeepGEMM #MatrixMultiplication #CUDA #AI #MachineLearning #OpenSource