
Berkeley Team Recreates DeepSeek's Success for $4,500: How a 1.5B Model Outperformed o1-preview

A groundbreaking development from UC Berkeley researchers has demonstrated that smaller AI models can achieve remarkable results through carefully designed training strategies. The team successfully trained a 1.5B parameter model, DeepScaleR-1.5B-Preview, to outperform OpenAI's o1-preview in mathematical reasoning tasks, spending just $4,500 in computation costs.

The "Short to Long" Training Strategy
The Berkeley team's success hinges on their innovative "short to long" training approach. This strategy begins with shorter context lengths and gradually expands them, allowing the model to develop efficient reasoning patterns before tackling more complex problems.
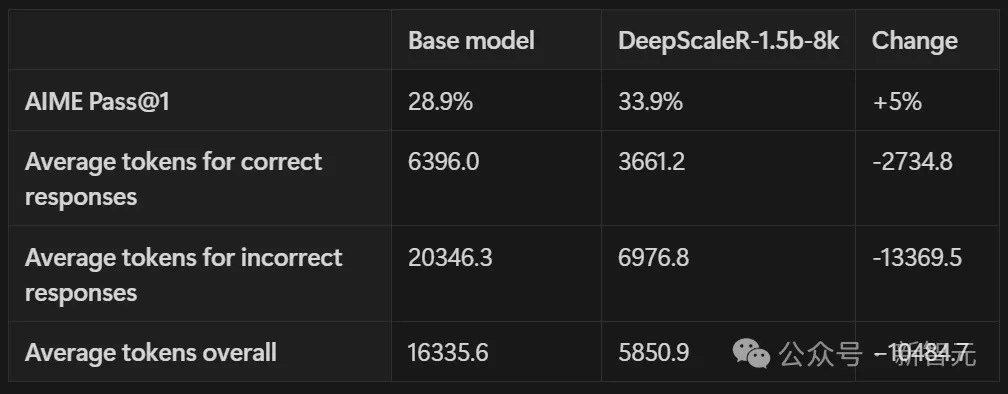
The training process consists of two key phases. Initially, the model is trained with an 8K token context length using DeepSeek's GRPO (Generalized Proximal Policy Optimization) method. This phase encourages efficient thinking patterns and helps reduce token usage by a factor of three while improving performance by 5% over the base model.
Following this initial phase, the context length is gradually increased to 16K and then 24K tokens, enabling the model to handle more challenging problems that previously remained unsolved. This progression proved crucial, as the model's average reward increased with each extension of the response length, ultimately leading to performance that surpassed o1-preview.
Technical Implementation
Dataset Construction
The research team built their training dataset from various mathematical competition sources, including:
American Invitational Mathematics Examination (AIME) problems from 1984-2023
American Mathematics Competition (AMC) questions through 2023
Problems from Omni-MATH and Still datasets
International mathematics competition questions
The data processing pipeline involved three critical steps:
First, answer extraction was performed using the gemini-1.5-pro-002 model to extract solutions from official Art of Problem Solving (AoPS) answers. Next, duplicate questions were removed using RAG and sentence-transformers embeddings, while ensuring no overlap between training and test sets. Finally, the team filtered out problems that couldn't be automatically evaluated using the sympy mathematical library, as these would introduce unstable reward signals during training.
After processing, the final dataset contained approximately 40,000 unique question-answer pairs.
The Training Process
The team's approach to training proved remarkably efficient. Using 3,800 A100 GPU hours (equivalent to about five days on 32 A100 GPUs), they achieved results that traditionally would have required considerably more resources. This efficiency represents an 18.42x cost reduction compared to traditional approaches.
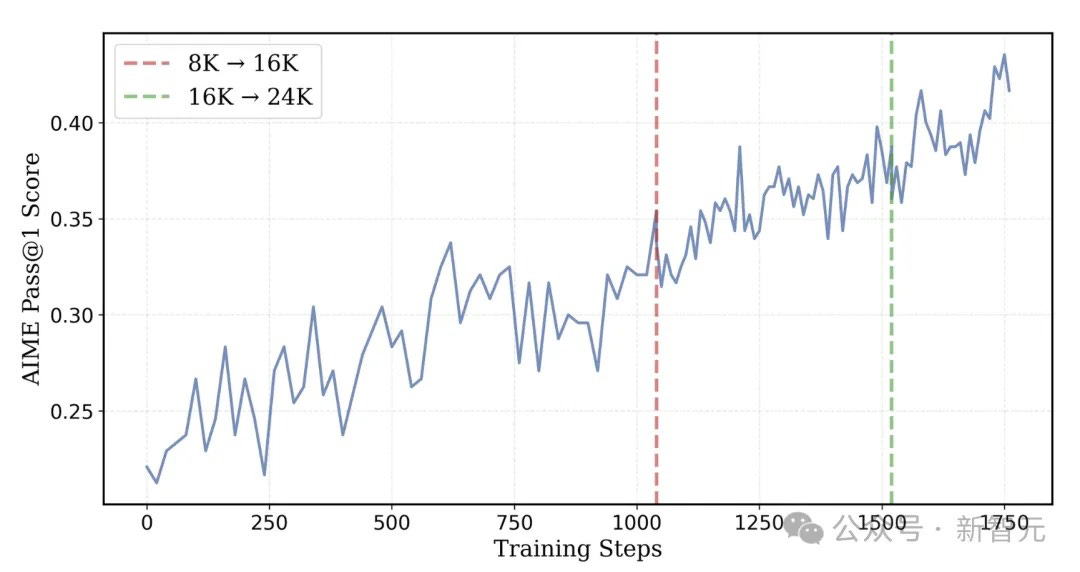
The training progression followed a carefully orchestrated sequence:
Initial 8K token phase using 8 A100 GPUs
Expansion to 16K tokens at step 1,040
Final increase to 24K tokens, utilizing 32 A100 GPUs
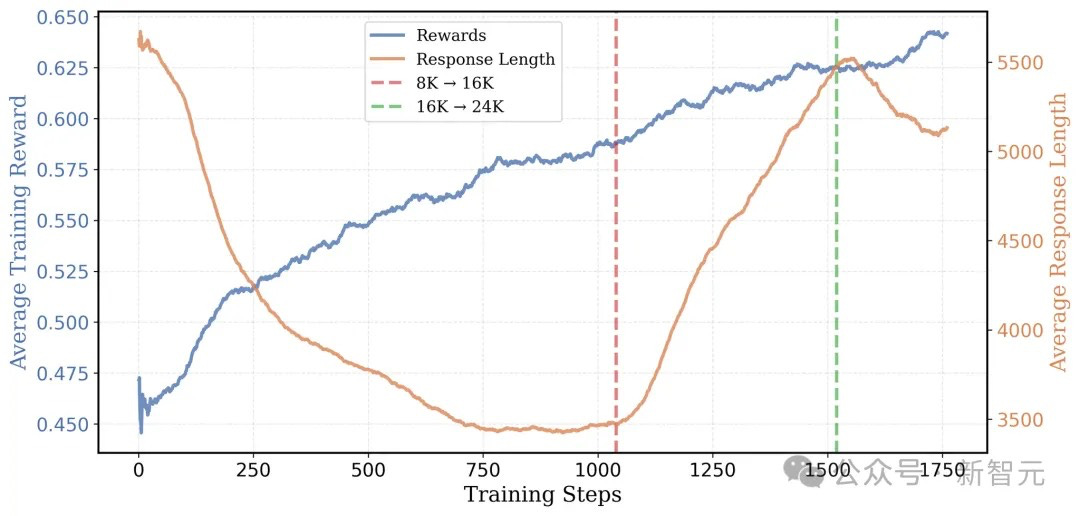
This gradual scaling approach proved crucial for both efficiency and performance. At each stage, the model demonstrated improved capabilities:
After the 8K token phase: Token usage reduced by 2/3 while improving accuracy
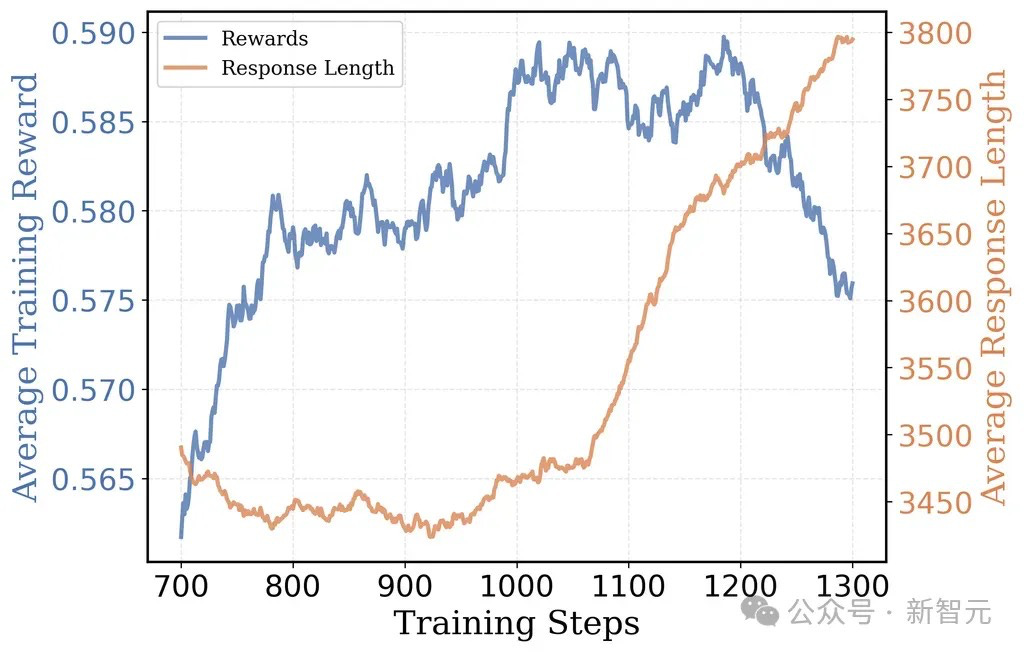
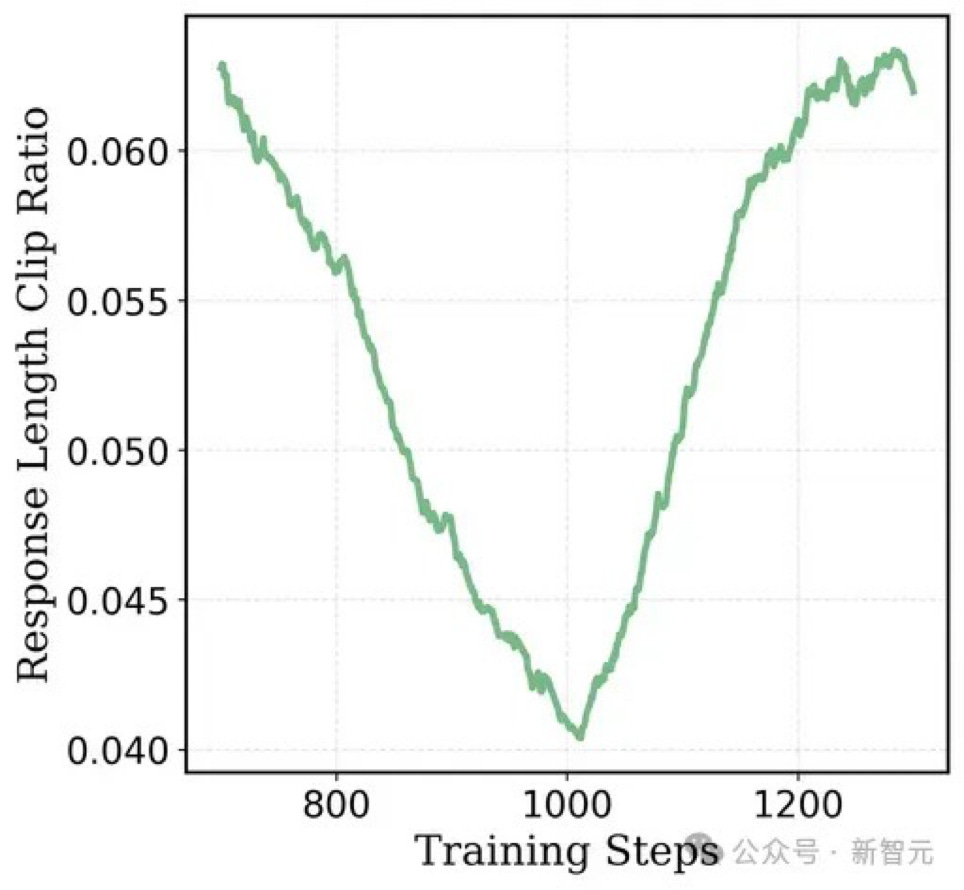
At 16K tokens: AIME accuracy reached 38%
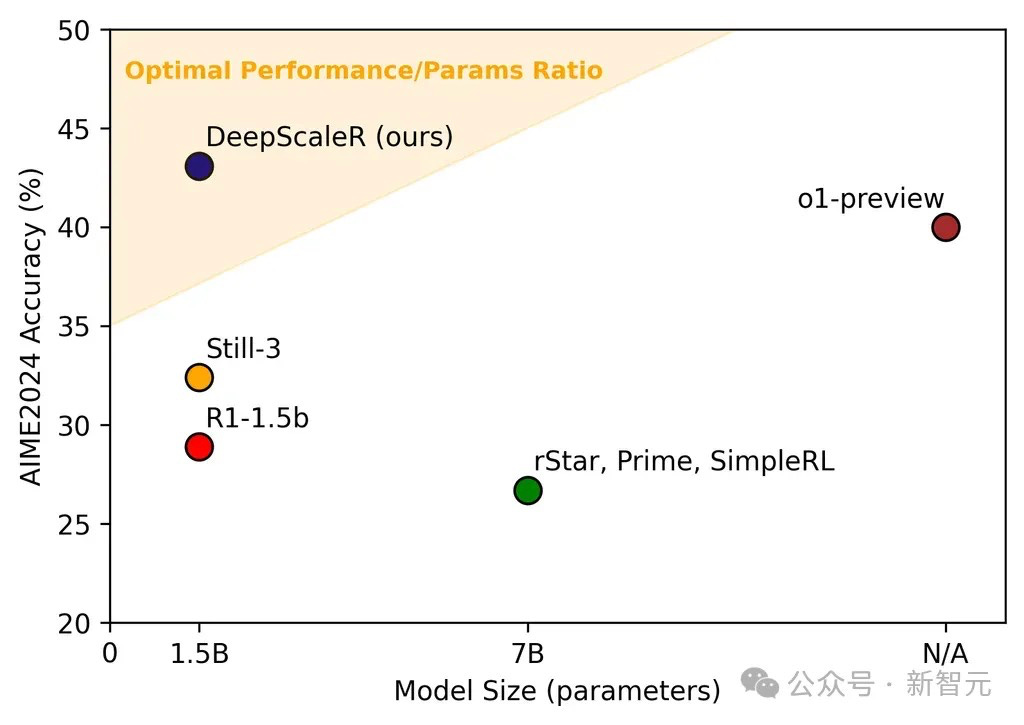
With 24K tokens: Final accuracy achieved 43.1%
Performance Benchmarks
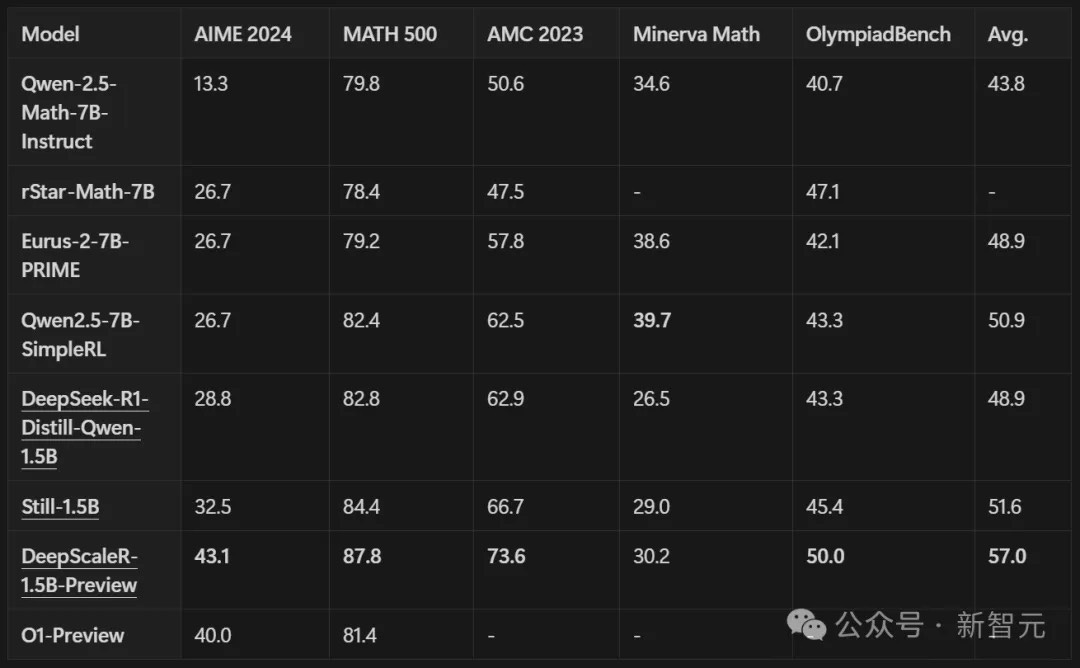
The model's performance was evaluated across multiple competitive mathematics benchmarks, including AIME 2024, AMC 2023, MATH-500, Minerva Math, and OlympiadBench. In all cases, DeepScaleR demonstrated significant improvements over the base model:
AIME 2024: 14.4% improvement
Overall performance: 8.1% enhancement
Competitive with models using many more parameters
Achieved o1-preview level performance with just 1.5B parameters
Key Insights and Discoveries
The research challenged several common assumptions about AI model training. Perhaps most significantly, it demonstrated that reinforcement learning can be highly effective with smaller models when combined with knowledge distillation. This finding contradicts the common belief that RL is only useful for large models.
The team's experiments showed that neither supervised fine-tuning nor reinforcement learning alone could achieve optimal results. Instead, the combination of high-quality supervised fine-tuning distillation with reinforcement learning proved key to unlocking the model's full reasoning potential.
Another crucial discovery involved the relationship between context length and training efficiency. Previous research suggested that training directly with longer context windows (16K tokens) showed no significant advantage over shorter ones (8K tokens). The team's graduated approach of starting with shorter contexts and progressively increasing them proved more effective.
Future Implications
This research opens new possibilities for making advanced AI capabilities more accessible to researchers and organizations with limited computational resources. By demonstrating that smaller models can achieve impressive results through careful training strategies, the team has provided a potential path forward for democratizing AI research.
The success of DeepScaleR suggests that future developments in AI might not necessarily require ever-larger models and massive computational resources. Instead, innovations in training strategies and efficient resource utilization might prove more important for advancing the field.
#AIResearch #MachineLearning #DeepLearning #Mathematics #BerkeleyAI #DeepSeek